Signal ledger / designed reading stage
浏览器基本原理
全面理解浏览器基本原理
Transition band / reading fieldLong-form note2023-02-07
Continue through the ledger
全面理解浏览器基本原理
进程是操作系统资源分配的最小单位;线程是计算机中独立运行、CPU 任务调度的最小单位。
进程是程序的运行实例,启动一个程序时,操作系统会为该程序创建一块内存,用于存放代码段、数据段和进程控制块(PCB)。
CPU 被视为计算机的大脑。CPU 的每个核心可以逐一处理许多不同的任务。与 CPU 不同,GPU 擅长同时处理多个简单任务,GPU 通常拥有数千个流处理器(Stream Processor)和数百个内存控制器,每个流处理器都可以处理一个数据元素,从而实现高度并行化的计算。
由于 GPU 的并行计算结构、高速内存、专用计算单元、更高的时钟频率等硬件优势,使得 GPU 可以更好地处理大规模简单相似数据。
单进程浏览器是指浏览器的所有功能模块都是运行在同一个进程里,这些模块包含了网络、插件、JavaScript 运行环境、渲染引擎和页面等。
现代浏览器基本已经从单进程发展成多进程的应用,每个标签页都属于一个独立的进程,同时浏览器的主进程、渲染、网络等也属于各自独立的进程。独立进程的好处是安全、稳定、流畅,但同样带来占用资源高的缺点。
多进程架构的浏览器解决了单进程浏览器存在的三大问题:
最新的 Chrome 浏览器包括:1 个浏览器(Browser)主进程、1 个 GPU 进程、1 个网络(NetWork)进程、多个渲染进程和多个插件进程
浏览器的主要工作流程:
浏览器进程将 URL 请求发送给网络进程,网络进程检查本地是否有可用缓存。
HTTP1.1 通过 Cache-Control
设置缓存策略,通过响应头携带不同的头字段及参数设置不同的缓存策略,常见的策略如下:
max-age=x(seconds),当再次请求的时间处于资源的 Date + max-age
时间内时,命中该策略,直接获取缓存结果。If-None-Match=ETag
与资源最新的 ETag 比较是否发生变化,如果没有变化则直接使用上次的缓存。如果不一致则重新请求。If-Modified-Since=Last-Modified
与资源最新的 Last-Modified 比较,检查资源最新更新时间如果没有变化则直接使用上次的缓存。如果不一致则重新请求。当没有可用缓存时,网络进程则会发起 DNS 解析。
当用户输入一个域名并提交给浏览器后,浏览器请求 DNS 进行 IP 查找,获取域名对应的服务器 IP 地址,并将 DNS 查询结果缓存。
通过访问 chrome://net-internals/#dns 可以查看记录的 DNS 缓存(目前需要到 Events 标签手动录制日志)
当一个网站有多个服务器地址时,DNS 服务器会对每个查询返回不同的 IP 地址,从而把访问均衡到不同的服务器上。
通过 DNS 获取到服务器 IP 后则会开始建立 TCP 链接。
网络协议分层从下往上依次为
TCP/IP 协议将应用层、表示层、会话层合并为应用层,物理层和数据链路层合并为网络接口层。
位码即 TCP 标志位,有 6 种标示:
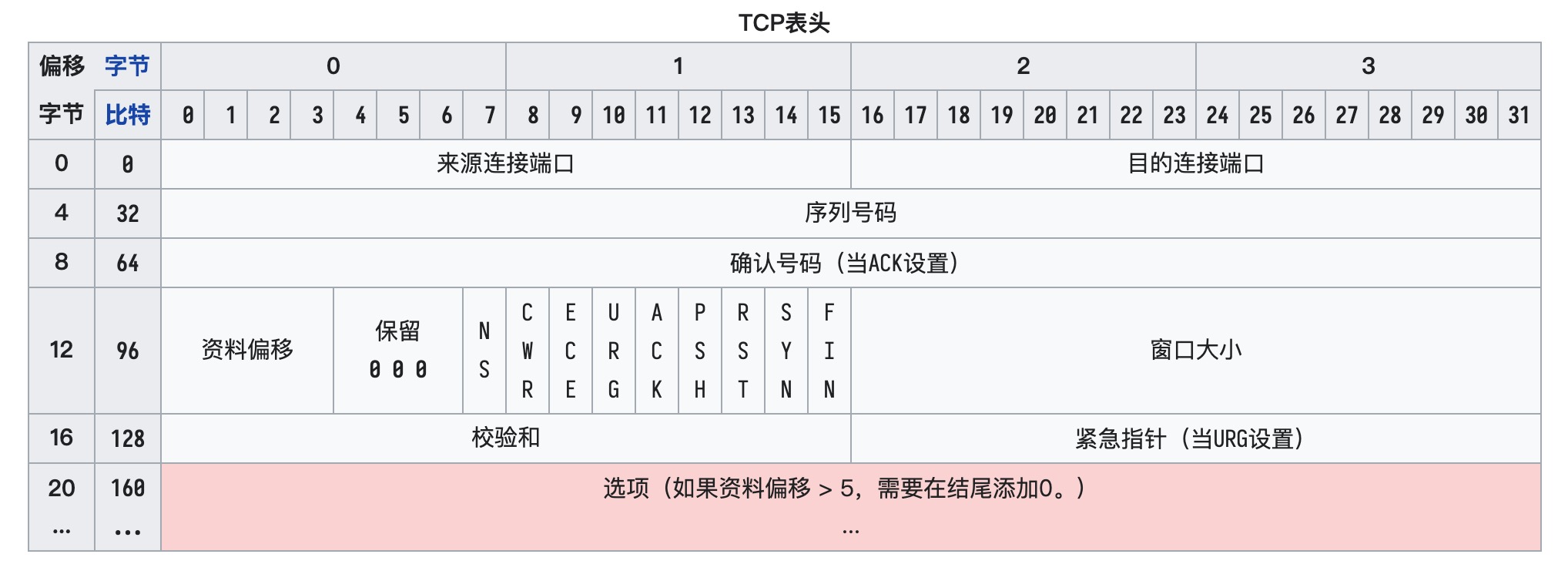
假设我们的请求由 Client 向 Server 发起,三次握手的流程如下:
第一次握手:Client 向 Server 发送一个 SYN 段,并指明 Client 的初始序列号,即 ISN(c).此时 Client 处于 SYN_SENT 状态。
Client 发送 SYN=1 seq=A
第二次握手:Server 收到 SYN 报文后,以自己的 SYN 报文作为应答,并指定自己的初始化序列号 ISN(s)。同时将 ISN(c)+1 作为 ACK 数值,此时 Server 处于 SYN_RCVD 的状态。
Server 发送 SYN=1 ACK=A+1 seq=B
第三次握手:Client 收到 SYN 报文后,检查数据正确后,发送一个 ACK 报文,同样把 Server 的
ISN(s)+1
作为 ACK 的值,此时 Client 处于 ESTABLISHED 状态。服务器收到 ACK 报文后,也处于 ESTABLISHED 状态,此时双方建立了连接。
Client 发送 ACK=B+1
这个环节有以下几个需要注意的点:
三次握手的必要性:如果 2 次,则 Server 无法确认 Client 是否能接受成功
半连接队列,全连接队列:半连接队列指 Server 第一次收到 SYN 响应之后等待 Client 响应处于 SYN_RCVD 状态的连接的队列。全连接队列指完成三次握手的连接队列。
SYN 攻击
Server 发送完 SYN-ACK 包,如果未收到确认则 Server 会进行重传,如果等待一段时间仍未收到确认,则进行下一次重传。如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。
Server 的资源分配是在二次握手时分配的,而 Client 的资源是在完成三次握手时分配的。所以如果伪造大量不存在的 Client 地址,并向 Server 不断地发送 SYN 包,Server 回复并等待确认,由于源地址不存在,因此 Server 会不断重发直至超时。这些伪造的请求将长时间占用连接队列,从而引起网络拥塞甚至系统瘫痪。SYN 攻击是一种典型的 DoS/DDoS 攻击。
常见的防御 SYN 攻击的方法有如下几种:
如何保证数据包传输的有序可靠
对字节流分段并进行编号然后通过 ACK 回复和超时重发这两个机制来保证。
对于 HTTPS 协议来说,相当于比 HTTP 多了一次 SSL/TLS 加密。HTTPS 解决数据传输安全问题的方案就是混合使用对称加密和非对称加密。TLS 需要经过 4 次握手:
客户端问候。Client 发起握手请求,并携带支持的协议版本、加密算法、压缩算法,以及客户端生成的随机数 client-random。
服务器回复响应并生成密钥。Server 发送响应请求,服务器保存随机数 client-random,选择对称加密和非对称加密的算法,然后生成随机数 service-random,向浏览器发送选择的加密套件、service-random 和数字证书(包含证书支持的域名、发行方和有效期等信息)。
Client 检查数字证书有效期、有效状态,获取公钥,发送经过公钥加密的随机数 pre-master secret。
对称加密密钥 KEY 由
ClientHelloRandom+ServerHelloRandom+pre-master secret通过加密方法生成
Client 发送经过 KEY 加密过的 finished 信号,此时 Client 就绪。
Server 拿出自己的私钥,解密出 finished 数据,并返回确认消息,Server 就绪。
TLS 加密中的几个重要概念:
pre-master key
由于 SSL 协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。对于 RSA 密钥交换算法来说,pre-master-key 本身就是一个随机数,再加上 hello 消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。pre
master 的存在在于 SSL 协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么 pre
master secret 就有可能被猜出来,那么仅使用 pre-master secret
作为密钥就不合适了,因此必须引入新的随机因素,那么 Client 和服务器加上 pre-master secret
三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了。
dog250
数字证书
在非对称加密通信过程中,服务器需要将公钥发送给 Client,在这一过程中,公钥很可能会被第三方拦截并替换,然后这个第三方就可以冒充服务器与 Client 进行通信,这就是传说中的“中间人攻击”(man in the middle attack)。解决此问题的方法是通过受信任的第三方交换公钥,具体做法就是服务器不直接向 Client 发送公钥,而是要求受信任的第三方,也就是证书认证机构 (Certificate Authority, 简称 CA)将公钥合并到数字证书中,然后服务器会把公钥连同证书一起发送给 Client,私钥则由服务器自己保存以确保安全。
建立连接后,Server 根据请求的报文信息进行响应。
如果响应的状态码是 301 或 302 时,说明服务器需要客户端重定向到另一个 URL,这时网络进程会从响应头的 Location 字段里面读取重定向的地址,然后再发起新的 HTTP 或者 HTTPS 请求,一切又将重头开始。
HTTP 的请求报文:
当 Server 处理后,则返回 HTTP 的响应报文:
请求头分为:
刚开始双方都处于 established 状态,假如是 Client 先发起关闭请求
第一次挥手:Client 发送一个 FIN 报文,报文中会指定一个序列号 X。此时 Client 处于 FIN_WAIT 状态
Client 发送 FIN=1 seq=X
第二次挥手:Server 收到 FIN 之发送 ACK 报文,并把 X+1 作为 ACK 报文的序列号值,此时 Server 处于 CLOSE_WAIT 状态
Server 回复 FIN=1 ACK=X+1 seq=Y
第三次挥手:如果 Server 需要断开连接,和 Client 的第一次挥手一样,发送 FIN 报文,且指定一个序列号 Z。此时 Server 处于 LAST_ACK 的状态,Client 处于 TIME_WAIT 状态
Server 发送 FIN=1 seq=Z ack=X+1
Client 发送确认信息,并等待 2MSL(Maximum Segment Lifetime)以确保接受完整数据,双方进入 CLOSED 状态
Client 回复 ack=Z+1 seq=X+1
涉及知识点:
解析文档是指将文档转化成为有意义的结构,也就是可让代码理解和使用的结构。解析得到的结果通常是代表了文档结构的节点树,它称作解析树或者语法树。一旦浏览器收到数据的第一块,它就可以开始解析收到的信息。“推测性解析”,“解析”是浏览器将通过网络接收的数据转换为 DOM 和 CSSOM 的步骤,通过渲染器把 DOM 和 CSSOM 在屏幕上绘制成页面。
当网络进程接受完成数据后,将文档数据提交给渲染进程,网络进程和渲染进程建立传输通道开始传输文档数据。等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
HTML 解析涉及到 Tokenization 和树的构造。HTML 标记包括开始和结束标记,以及属性名和值。解析器将标记化的输入解析到文档中,构建文档树。
生成的 DOM 树描述了文档的内容, <html>
元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点。DOM 节点的数量越多,构建 DOM 树所需的时间就越长。
标记化算法
该算法使用状态机来表示。每一个状态接收来自输入信息流的一个或多个字符,并根据这些字符更新下一个状态。当前的标记化状态和树结构状态会影响进入下一状态的决定。这意味着,即使接收的字符相同,对于下一个正确的状态也会产生不同的结果,具体取决于当前的状态。
这个算法输入为 HTML文本,输出为
HTML标记,也成为标记生成器。其中运用有限自动状态机来完成。即在当前状态下,接收一个或多个字符,就会更新到下一个状态。
<html>
<body>
Hello world
</body>
</html>初始状态是 数据状态。遇到字符 < 时,状态更改为
标记打开状态。接收一个 a-z 字符会创建“起始标记”,状态更改为
标记名称状态。这个状态会一直保持到接收 >
字符。在此期间接收的每个字符都会附加到新的标记名称上。遇到 > 标记时,会发送当前的标记,状态改回
数据状态。目前 html 和 body 标记均已发送。
现在我们回到 数据状态,接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收
</body> 中的 <。我们将为 Hello world 中的每个字符都发送一个字符标记。现在回到
标记打开状态。接收下一个输入字符 / 时,会创建 end tag token 并改为
标记名称状态,我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到 数据状态。
树构建算法
在创建解析器的同时,也会创建 Document 对象。在树构建阶段,以 Document 为根节点的 DOM 树也会不断进行修改,向其中添加各种元素。标记生成器发送的每个节点都会由树构建器进行处理。
规范中定义了每个标记所对应的 DOM 元素,这些元素会在接收到相应的标记时创建。这些元素不仅会添加到 DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于纠正嵌套错误和处理未关闭的标记。其算法也可以用状态机来描述。这些状态称为“插入模式”。
同样以上述 html 代码为例,树构建阶段的输入是一个来自标记化阶段的标记序列。第一个模式是
initial mode。接收 HTML 标记后转为 before html
模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。然后状态将改为
before head。此时我们接收 body 标记。即使我们的示例中没有 head 标记,系统也会隐式创建一个
HTMLHeadElement,并将其添加到树中。
现在我们进入了 in head 模式,然后转入 after head 模式。系统对 body
标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为 in body。
现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点。
接收 body 结束标记会触发 after body 模式。现在我们将接收 HTML 结束标记,然后进入
after after body 模式。接收到文件结束标记后,解析过程就此结束。
预加载扫描器
当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个 CSS 文件时,解析也可以继续进行,但是对于
<script>
标签(特别是没有 async 或者 defer 属性)会阻塞渲染并停止 HTML 的解析。尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈
浏览器构建 DOM 树时,这个过程占用了主线程。当这种情况发生时,预加载扫描仪将解析可用的内容并请求高优先级资源,如 CSS、JavaScript 和 web 字体。多亏了预加载扫描器,我们不必等到解析器找到对外部资源的引用来请求它。它将在后台检索资源,以便在主 HTML 解析器到达请求的资源时,它们可能已经在运行,或者已经被下载。
<link rel="stylesheet" src="styles.css" />
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description" />
<script src="anotherscript.js" async></script>在这个例子中,当主线程在解析 HTML 和 CSS 时,预加载扫描器将找到脚本和图像,并开始下载它们。为了确保脚本不会阻塞进程,当 JavaScript 解析和执行顺序不重要时,可以添加 async 属性或 defer 属性。等待获取 CSS 不会阻塞 HTML 的解析或者下载,但是它的确阻塞 JavaScript,因为 JavaScript 经常用于查询元素的 CSS 属性。
阻塞
解析到需要加载的资源,如 script , img , css 资源时,有可能会引起阻塞的问题。
CSS 样式文件一般有三种来源:
通过这三种来源,HTML 引入了 CSS 数据,但浏览器使用它还需要经过解析才能使用,解析器将 CSS 文件解析成 StyleSheet 对象,且每个对象都包含 CSS 规则,CSS 规则对象则包含选择器和声明对象,以及其他与 CSS 语法对应的对象。浏览器遍历 CSS 中的每个规则集,根据 CSS 选择器创建具有父、子和兄弟关系的节点树。可以通过
document.styleSheets 查看解析后的数据结构。
渲染步骤包括构建渲染树、布局、绘制,在某些情况下还包括合成。在解析步骤中创建的 CSSOM 树和 DOM 树组合成一个 Render 树,然后用于计算每个可见元素的布局,然后将其绘制到屏幕上。
在 DOM 树构建的同时,浏览器还会构建渲染树。这是由可视化元素按照其显示顺序而组成的树,也是文档的可视化表示。它的作用是让页面按照正确的顺序绘制内容。
构建渲染树时,通过计算每个元素的节点属性、样式属性来计算每一个呈现对象的可视化属性。样式计算存在以下难点:
浏览器通过下面几种方法去解决这些难点:
渲染树上运行布局以计算每个节点的几何体。布局是确定渲染树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。Reflow(回流) 是对页面的任何部分或整个文档的任何后续大小和位置的确定。
构建渲染树后,开始布局。渲染树标识显示哪些节点(即使不可见)及其计算样式,但不标识每个节点的尺寸或位置。为了确定每个对象的确切大小和位置,浏览器从渲染树的根开始遍历它。第一次确定节点的大小和位置称为 Layout(布局)。随后对节点大小和位置的重新计算称为 Reflow。
布局通常具有以下模式:
如果渲染器在布局过程中需要换行,会立即停止布局,并告知其父代需要换行。父代会创建额外的渲染器,并对其调用布局。
布局有几种优化手段:
Dirty 位系统
为避免对所有细小更改都进行整体布局,浏览器采用了一种“dirty 位”系统。如果某个渲染器发生了更改,或者将自身及其子代标注为“dirty”,则需要进行布局。有两种标记:“dirty”和“children are dirty”。“children are dirty”表示尽管渲染器自身没有变化,但它至少有一个子代需要布局。
全局布局和增量布局
全局布局:指触发了整个呈现树范围的布局,呈现器的全局样式更改或者屏幕大小调整都会触发全局布局。
增量布局:采用增量方式,也就是只对 dirty 呈现器进行布局(这样可能存在需要进行额外布局的弊端)。
对于影响所有渲染器的全局样式更改,或屏幕大小调整,往往会触发整个呈现树范围的布局。而当渲染器为 dirty 时,会异步触发增量布局。
异步布局和同步布局
全局布局往往是同步触发的。有时,当初始布局完成之后,如果一些属性(如滚动位置)发生变化,布局就会作为回调而触发。增量布局是异步执行的。
优化方式
浏览器的优化策略
如果布局是由 大小调整 或 渲染器的位置(而非大小)改变而触发的,那么可以从缓存中获取渲染器的大小,而无需重新计算。在某些情况下,只有一个子树进行了修改,因此无需从根节点开始布局。这适用于在本地进行更改而不影响周围元素的情况,例如在文本字段中插入文本(否则每次键盘输入都将触发从根节点开始的布局)。
因为这个优化方案,所以你每改一次样式,它就不会回流(Reflow)或重绘(Repaint)一次。但是有些情况,如果我们的程序需要某些特殊的值,那么浏览器需要返回最新的值,而会有一些样式的改变,从而造成频繁的回流和重绘。比如获取下面这些值,浏览器会马上进行回流:
减少重绘重排的优化策略
布局处理
布局通常具有以下模式:
宽度计算
渲染器宽度是根据容器块的宽度、渲染器样式中的 width 属性以及边距和边框计算得出的。
例如以下 div 的宽度:
<div style="width: 30%"></div>将由 Webkit 计算如下(BenderBox 类,calcWidth 方法):
容器的宽度取容器的 availableWidth 和 0 中的较大值。availableWidth 在本例中相当于 contentWidth,计算公式如下:
clientWidth() - paddingLeft() - paddingRight()clientWidth 和 clientHeight 表示一个对象的内部(除去边框和滚动条)。
元素的宽度是 width 样式属性。它会根据容器宽度的百分比计算得出一个绝对值。
然后加上水平方向的边框和补白。
换行
如果渲染器在布局过程中需要换行,会立即暂停布局,并告知其父代需要换行。父代会创建额外的渲染器,并对其调用布局。
最后一步是将各个节点绘制到屏幕上,第一次出现的节点称为 first meaningful paint。在绘制或光栅化阶段,浏览器将在布局阶段计算的每个框转换为屏幕上的实际像素。绘画包括将元素的每个可视部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换的元素(如按钮和图像)。
为了确保平滑滚动和动画,占据主线程的所有内容,包括计算样式,以及 Reflow 和 Paint,必须让浏览器在 16.67 毫秒内完成。为了确保 Repaint 的速度比初始 Paint 的速度更快,屏幕上的绘图通常被分解成数层。如果发生这种情况,则需要进行合成。
Paint 可以将布局树中的元素分解为多个层。将内容提升到 GPU 上的层(而不是 CPU 上的主线程)可以提高 Paint 和重新 Paint 性能。有一些特定的属性和元素可以实例化一个层,包括
<video> 和
<canvas>,任何 CSS 属性为 opacity、3D 转换、will-change 的元素,还有一些其他元素。这些节点将与子节点一起 Paint 到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。
层可以提高性能,但是它以内存管理为代价,因此不应作为 web 性能优化策略的一部分过度使用。
全局绘制和增量绘制
绘制顺序
绘制的顺序其实就是元素进入 堆栈样式上下文 的顺序。这些堆栈会从后往前绘制,因此这样的顺序会影响绘制。块呈现器的堆栈顺序如下:
动态变化
在网页元素发生变化时,浏览器会尽可能做出最小的响应:
渲染引擎采用了单线程
渲染引擎是单线程的。除网络操作外,几乎所有操作都发生在单个线程中。在 Firefox 和 Safari 中,是浏览器主线程。在 Chrome 中,是选项卡进程主线程。
浏览器主线程是一个事件循环,它是一个无限循环,永远处于接受处理状态,并等待事件(如布局和绘制事件)发生,并进行处理。
合成是一种将页面分成若干层,然后分别对它们进行光栅化,最后在一个单独的线程 - 合成线程(compositor thread)里面合并成一个页面的技术。当用户滚动页面时,由于页面各个层都已经被光栅化了,浏览器需要做的只是合成一个新的帧来展示滚动后的效果罢了。页面的动画效果实现也是类似,将页面上的层进行移动并构建出一个新的帧即可。
为了实现合成技术,我们需要对元素进行分层,确定哪些元素需要放置在哪一层,主线程需要遍历渲染树来创建一棵层次树(Layer Tree)。一旦 Layer Tree 被创建,渲染顺序被确定,主线程会把这些信息通知给合成器线程,合成器线程开始对层次数的每一层进行光栅化。有的层的可以达到整个页面的大小,所以合成线程需要将它们切分为一块又一块的小图块(Tiles),之后将这些小图块分别进行发送给一系列光栅线程(raster threads)进行光栅化,结束后光栅线程会将每个图块的光栅结果存在 GPU Process 的内存中。
为了优化显示体验,合成线程可以给不同的光栅线程赋予不同的优先级,将那些在视口中的或者视口附近的层先被光栅化。
当图层上面的图块都被栅格化后,合成线程会收集图块上面叫做绘画四边形(draw quads)的信息来构建一个合成帧(compositor frame)。
以上所有步骤完成后,合成线程就会通过 IPC 向浏览器进程(browser process)提交(commit)一个渲染帧。这个时候可能有另外一个合成帧被浏览器进程的 UI 线程(UI thread)提交以改变浏览器的 UI。这些合成帧都会被发送给 GPU 从而展示在屏幕上。如果合成线程收到页面滚动的事件,合成线程会构建另外一个合成帧发送给 GPU 来更新页面。
合成的好处在于这个过程没有涉及到主线程,所以合成线程不需要等待样式的计算以及 JavaScript 完成执行。这就是为什么合成器相关的动画最流畅,如果某个动画涉及到布局或者绘制的调整,就会涉及到主线程的重新计算,自然会慢很多。
如何创建独立图层?
实际优化点:
浏览器接收到网站页面文档后,会将文档中的标记语言解析为 DOM 树。DOM 树和 CSS 结合形成浏览器构建页面的渲染树。渲染树中包含了大量的渲染元素,每个渲染元素会被分到单独一个图层中,每个图层又会被加载到 GPU 形成渲染纹理,而图层在 GPU 中 transform 是不会触发 repaint 的,这点非常类似 3D 绘图功能,最终这些使用 transform 的图层都会由独立的合成器进程进行处理。
CSS transform 创建新的复合图层,可以被 GPU 直接用来执行 transform 操作。在 Chrome 开发者工具中开启 Show Layer Border 选项后,每个复合图层就会显示一条黄色的边界。
每个页面元素都有一个独立的渲染进程,包含了主线程和合成线程。
主线程 负责脚本的执行、CSS 样式计算、计算布局位置(Layout)、将页面元素绘制成位图(Paint)、发送位图给合成线程(Compositor Thread)合成线程 则主要负责将位图发送给 GPU、计算页面的可见部分和即将可见部分(滚动)、通知 GPU 绘制位图到屏幕上。加上一个点,GPU 对于动画图形的渲染处理比 CPU 要快,那么就可以达到加速的效果当我们通过某种方法引起浏览器的 reflow 时,需要重新经历样式计算(Style Calculation)和布局(Layout)阶段,导致浏览器重新计算页面中每个 DOM 元素的尺寸及重新布局,伴随着重新进行 repaint,这个过程是非常耗时的。为了把代价降到最低,当然最好只留下合成(Composite)这个步骤最好。假设当我们改变一个容器的样式时,影响的只是它自己,并且还无需重绘,直接通过 GPU 中改变纹理的属性来改变样式,岂不是更好?
就是让 DOM 元素拥有自己的层(Layer)。有了层的概念,让我们从层的概念再来看浏览器的渲染过程:
可以将这个过程理解为设计师的 PS 文件。在 PS 源文件中,一个图像是由若干个图层相互叠加而展示出来的。分成多个图层的好处就是每个图层相对独立,修改方便,对单个图层的修改不会影响到页面上的其他图层。因此层(Layer)存在的意义在于:用最小的代价来改变某个页面元素。可以将某个 CSS 动画或某个 JS 交互效果抽离到一个单独的渲染层,来达到加速渲染的目的。
如何开启硬件加速?
CSS 中以下几个属性能触发硬件加速:
如果有一些元素不需要用到上述属性,但是需要触发硬件加速效果,可以使用硬编码的技巧来诱导浏览器开启硬件加速。
.element {
-webkit-transform: translateZ(0);
-moz-transform: translateZ(0);
-ms-transoform: translateZ(0);
-o-transoform: translateZ(0);
transform: translateZ(0);
transform: rotateZ(360deg);
transform: translate3d(0, 0, 0);
}这段代码的作用就是让浏览器执行 3D transform。浏览器通过该样式创建了一个独立图层,图层中的动画则有 GPU 进行预处理并且触发了硬件加速。
如果某个元素的背后是一个复杂元素,那么该元素的 repaint 操作就会耗费大量的资源,此时也可以使用上面的技巧来减少性能开销。
注意事项: